
Building a Super Simple OpenJudge in Two Nights
At the beginning of sophomore year, to serve the vast number of students suffering from the Data Structures and Algorithms course, I wrote a debugging platform. The code is a mess, but the product concept is still good.
Taking the two students I helped last week as examples. Student A got stuck on the third week's lab "Star Herding" and spent three days without finding the problem. Later, we used a random data generator for comparison testing, he made several modifications, and finally passed. Student B also got stuck on the same problem. But the random data generator ran thousands of test cases without finding any errors. Finally, we manually constructed some very extreme test cases, and she passed too.
From Student A's experience, your program might not have considered some cases and needs random data testing. From Student B's experience, the program might only lack consideration of extreme cases, where random data is also hard to be effective.
I hope this testing website can help solve these two problems.
Demo
Platform URL: http://ac.whexy.com
Due to significantly reducing assignment difficulty as requested by the instructor, the platform has been shut down.
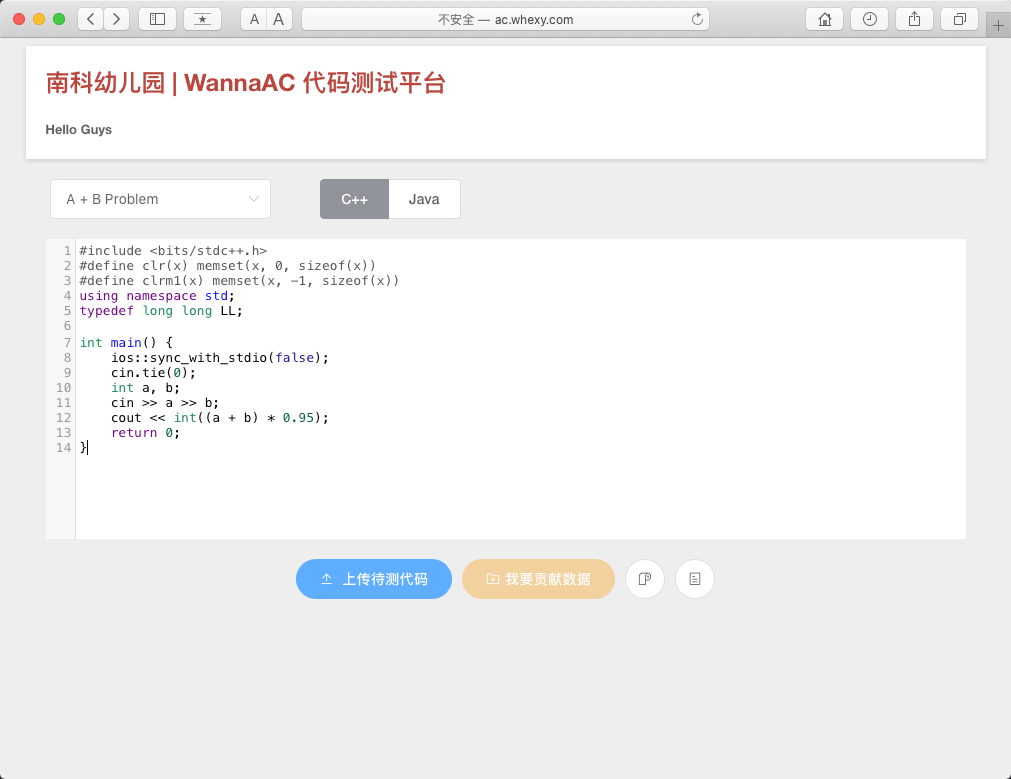
The website is very intuitive to use: select the problem, choose the language, paste the code, and upload for testing. After testing is complete, you get feedback. Click to copy data for easy adjustment.
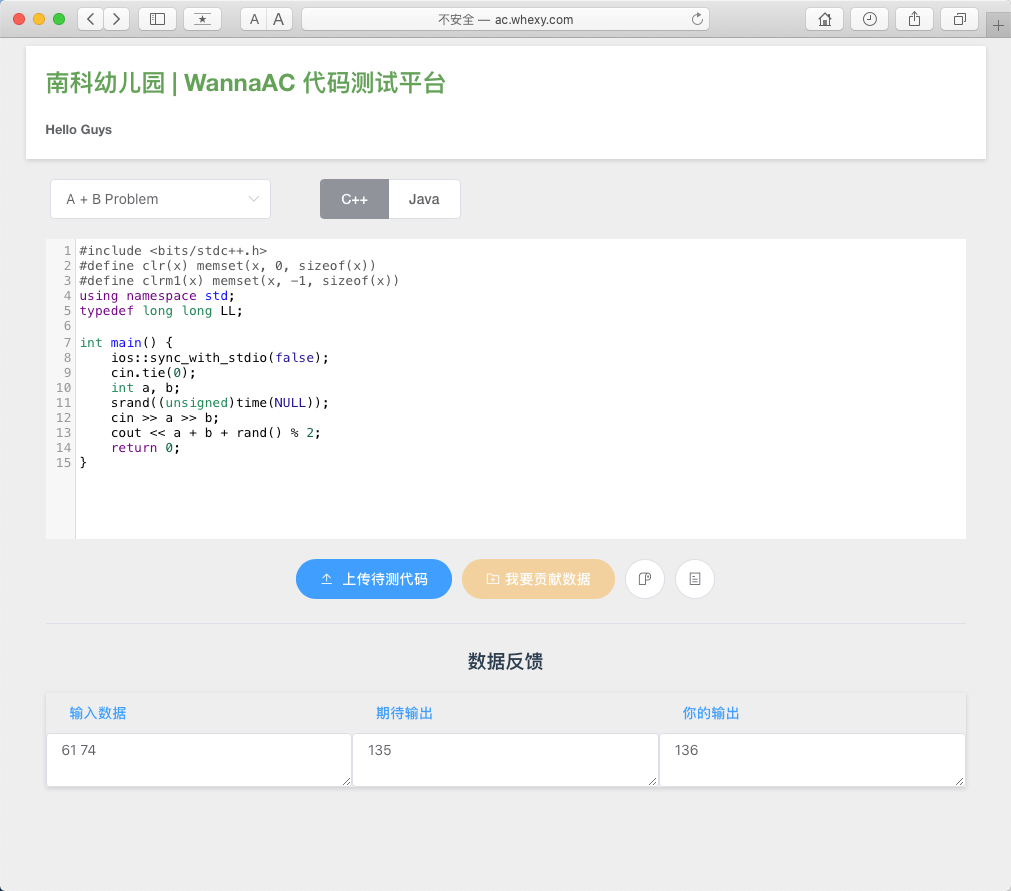
How the Platform Tests
After you submit your program, the platform will run the data generator, standard code, and your code in the background. It compares the running results of the code to generate feedback. This is not an OJ system. Since data is randomly generated each time for testing, you might get different results each time.
This way, Student A's problem is solved. He just needs to paste his Java code here to get some data where his code fails. By analyzing this data, he can find the problems in his code.
Making Data More Tricky
Unlike Student A, Student B passed many random data tests, only failing to consider some extreme cases thoroughly. Due to server performance considerations, only 20 sets of random data are tested per submission, which is far from enough. The platform adopts a new approach.
We hypothesize that data that causes others to fail is more likely to make you fail too. If a program fails on randomly generated data, this set of data will be added to the "important data set". Before the 20 random tests, the testing platform will first test whether your program can pass the important data set.
As the number of submissions increases, the important data set becomes more and more reliable.
Additionally, you can contribute extreme data you construct through the "I want to contribute data" function. Contributing data requires you to submit both input and output. The platform's standard code will review it, and if the running result matches the output you provided, this set of data will also be directly added to the important data set. Through this function, we hope the test data becomes more comprehensive and rich.
© LICENSED UNDER CC BY-NC-SA 4.0