
Alligator In Vest - My first research work
现在我要介绍我们最近的工作。我们叫它"Investigator"。Investigator 使用硬件特性来诊断 Arm 上的并发错误。

并发错误

首先,让我们看一个简单的并发错误例子。有两个线程共享一个名为 big_buf 的变量。线程1试图从文件描述符中读取内容,并将其放入 big_buf 数组中。同时,线程2有一个较小的 buf,想要执行字符串复制。由于 buf 的大小较小,它必须检查 big_buf 中的内容,确保不超过长度。到目前为止,程序似乎运行正常。

然而,线程的调度是由操作系统控制的。由于两个线程没有任何类型的锁,它可能按以下顺序执行:在读取之前执行长度检查。在读取之后执行字符串复制。现在字符串复制是危险的,因为它引入了缓冲区溢出。文件中的内容可能会覆盖运行时堆栈,这是一个严重的安全风险。
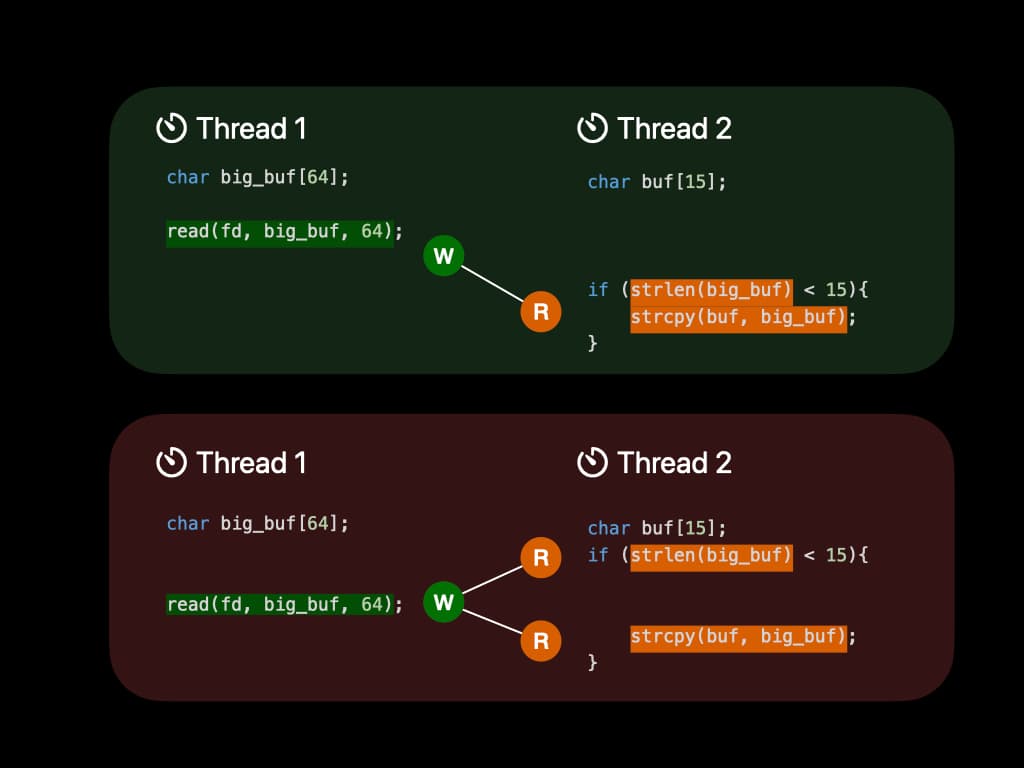
我们从这个例子中学到的是并发错误很难发现。这些错误在执行时不是100%触发的。此外,我们可以归纳出一些结论。在前一种情况下,big_buf 首先被线程1写入,然后被线程2读取。它遵循"W-R"模式。在后一种情况下,big_buf 被线程2读取,然后被线程1写入,再被线程2读取。它遵循"R-W-R"模式。
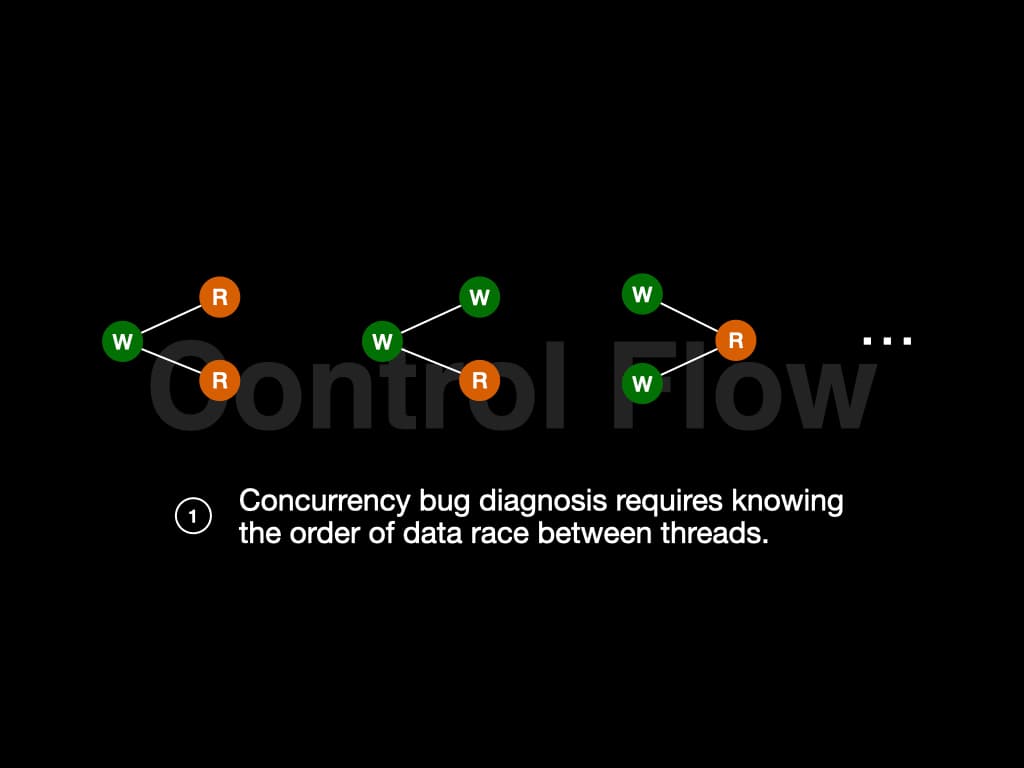
许多不同的模式可能导致并发错误,如"R-W-R"、"W-W-R"、"W-R-W"等。要找出这些模式是否存在于我们的程序中,我们需要知道线程之间数据竞争的顺序。换句话说,我们需要知道控制流。

例子中还有另一个关键事实。线程1试图从文件描述符中读取内容。如果内容本身的长度小于15怎么办?那就不会有错误!程序的输入会影响其行为。系统调用 read() 是向程序引入不确定性的一个例子。

程序运行时还有更多非确定性因素,如 write()、ioctl() 等。我们需要知道这些非确定性因素的影响,以进一步诊断错误。换句话说,我们需要知道数据流。
低开销故障诊断
所以 investigator 找到了一种低开销诊断这些错误的方法。
每次我们运行并发程序时,控制流都略有不同。由于线程的执行必须在线记录,而客户不愿意使用开销很大的在线记录,系统不能消耗太多时间。
回想一下,并发错误诊断需要知道控制流和数据流——以低开销获得这些信息有很多挑战。
控制流
首先,让我们谈谈控制流。要跟踪数据竞争的细粒度交错,人们可能需要将代码注入内核,比如在上下文切换时写日志。这将产生大约200%的性能开销。
Investigator 使用硬件辅助记录解决方案。在硬件的帮助下,我们声称系统几乎没有引入开销。

帮助我们跟踪执行的神奇硬件叫做 arm Embedded Trace Macrocell (ETM)。如果你熟悉 Intel Processor Trace (Intel PT),你可能会发现这两个硬件提供相同的功能。
ETM 可以记录执行指令的内存地址,将其编码为小流,然后放入称为 ETR 的缓冲区中。

我们做了一些额外的工作来充分利用 ETM 的功能,帮助我们诊断并发程序。
首先,我们使用称为"Counter"的硬件组件为 ETM 输出生成细粒度时间戳。通过时间戳,我们可以知道执行顺序,即使跨不同处理器也是如此。
其次,我们利用 ETR 分配专用的物理内存块作为 ETM 的缓冲区。这意味着 ETM 输出流直接发送到 RAM。我们可以避免频繁暂停程序来获取 ETM 输出,这将减轻性能负担。
第三,我们使用另一个称为"性能监控单元(PMU)"的硬件组件来自动从缓冲区中提取跟踪。我们使用 PMU 来计算执行指令的数量。当指令数量超过我们设置的阈值时,硬件中断将发送到内核,我们预定义的处理程序可以提取跟踪。
数据流
下一个挑战是构建数据流。由于 ETM 可以跟踪 CPU 中执行的每条指令,重新运行控制流来获取数据流应该是可以的。然而,使用 ETM 来跟踪内核和共享库有点浪费。
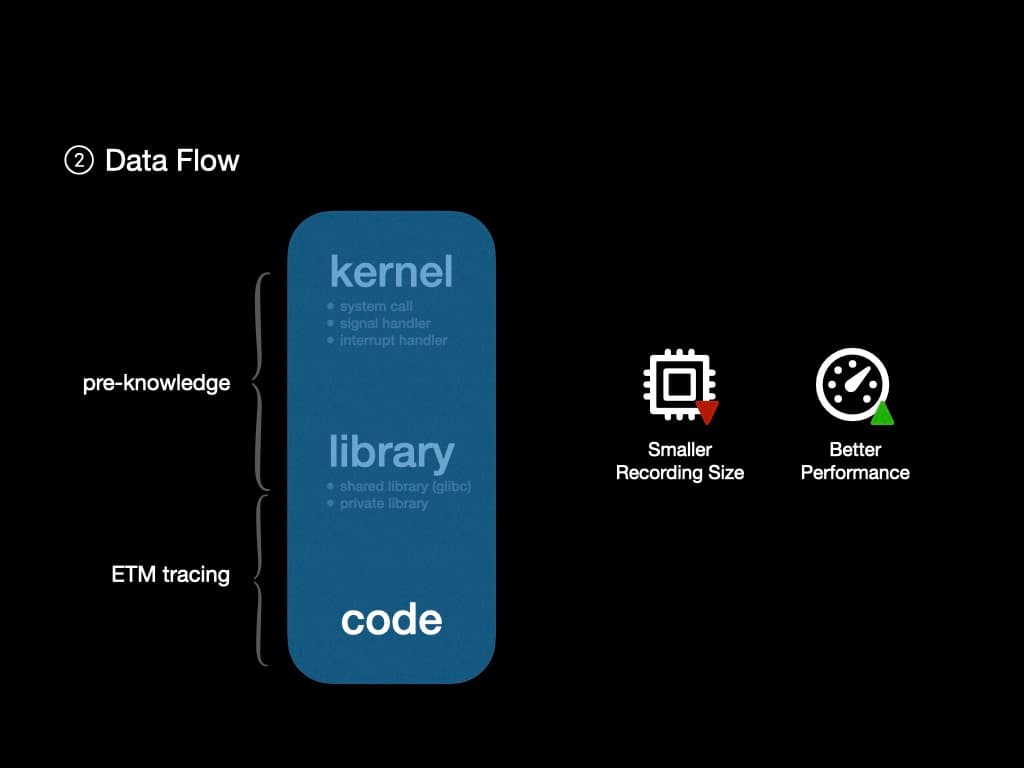
由于我们对内核和一些共享库(如 glibc)有预先的了解,我们可以忽略它们内部的控制流和数据流,而专注于用户空间程序。
因此我们可以进一步减少 ETM 输出的大小。ETM 输出越小,我们需要从 RAM 中提取它们的频率就越低,这导致更好的性能。
我们没有跟踪完整的执行,而是实现了一个轻量级事件捕获器来记录系统调用、异常、信号和中断。
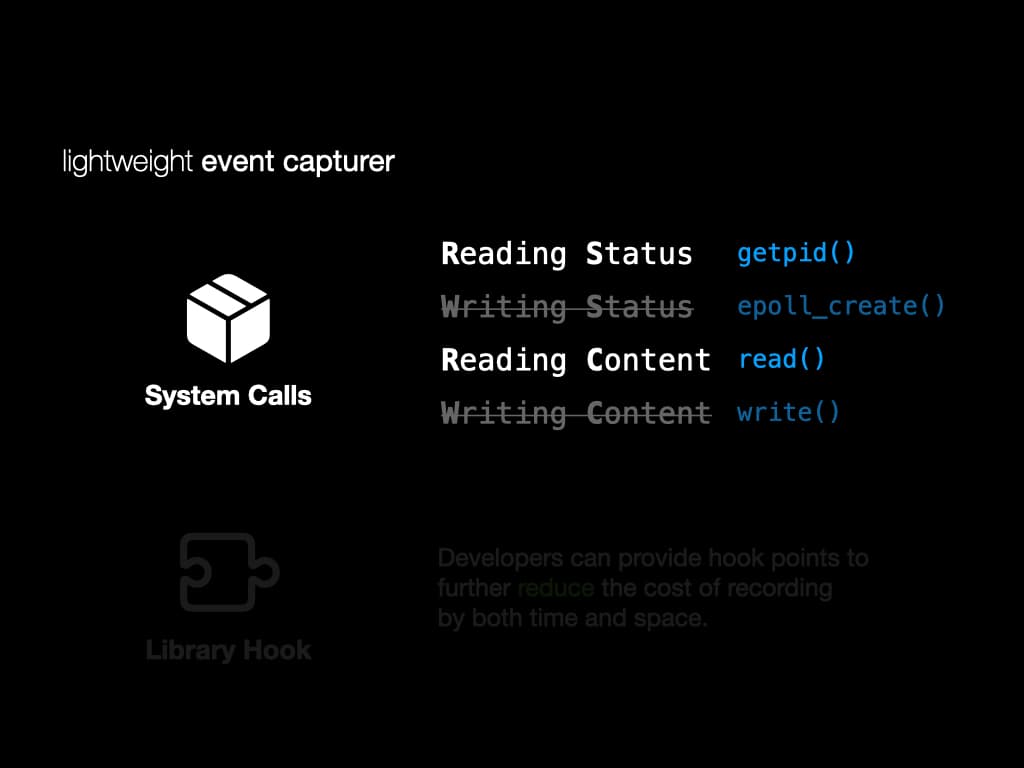
对于系统调用,我们将它们分为四组。"读取状态"、"写入状态"、"读取内容"和"写入内容"。对于 RS 和 RC,这些系统调用影响数据流,所以我们会详细记录它们。对于 WS 和 WC,这些系统调用不会影响数据流,所以我们只记录它们的返回值。

我们还实现了 glibc 的库钩子来降低记录这个动态库的成本。被调用的库函数被记录以重建数据流。
开发人员也可以提供自己的钩子来进一步降低记录成本。(我们还在长期实验中展示了如何做到这一点)

总结,我们使用 ETM 生成控制流。我们使用前向重现和轻量级事件捕获器来构建数据流。
多处理器程序的控制流
我们刚才谈到了使用 ETM 中的时间戳来生成控制流。当程序在多个处理器之间执行时可能会有一些问题。
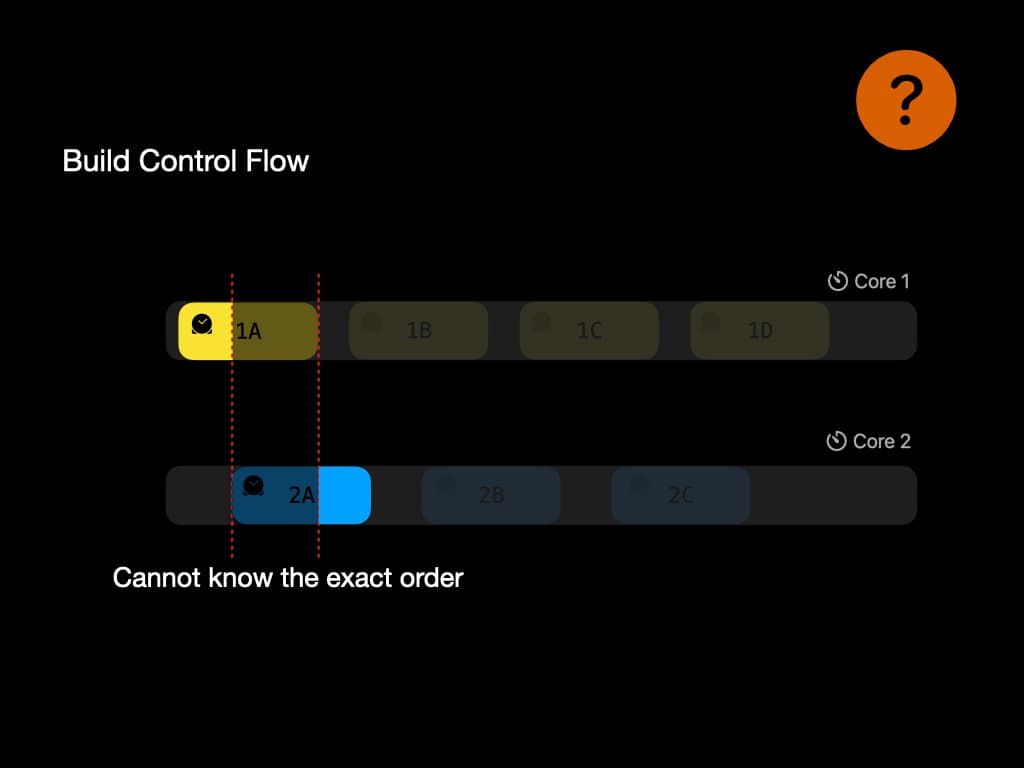
例如,时间戳可能不够精确,无法给出确切的执行顺序。在这个例子中,1A 和 2A 之间有重叠。因此我们可能丢失关于数据竞争的信息。这个问题在研究人员中仍然是一个难题。

我们的解决方案是使用"计数器"硬件生成尽可能多的时间戳,使其足够精确。在我们的测试中,在数据竞争发生的最坏情况下,99.34%的指令可以按正确顺序记录。
根本原因
程序故障后,我们有了控制流和数据流。为了找到故障的根本原因,我们使用这些方法:混合分析、模式匹配和自适应收集。
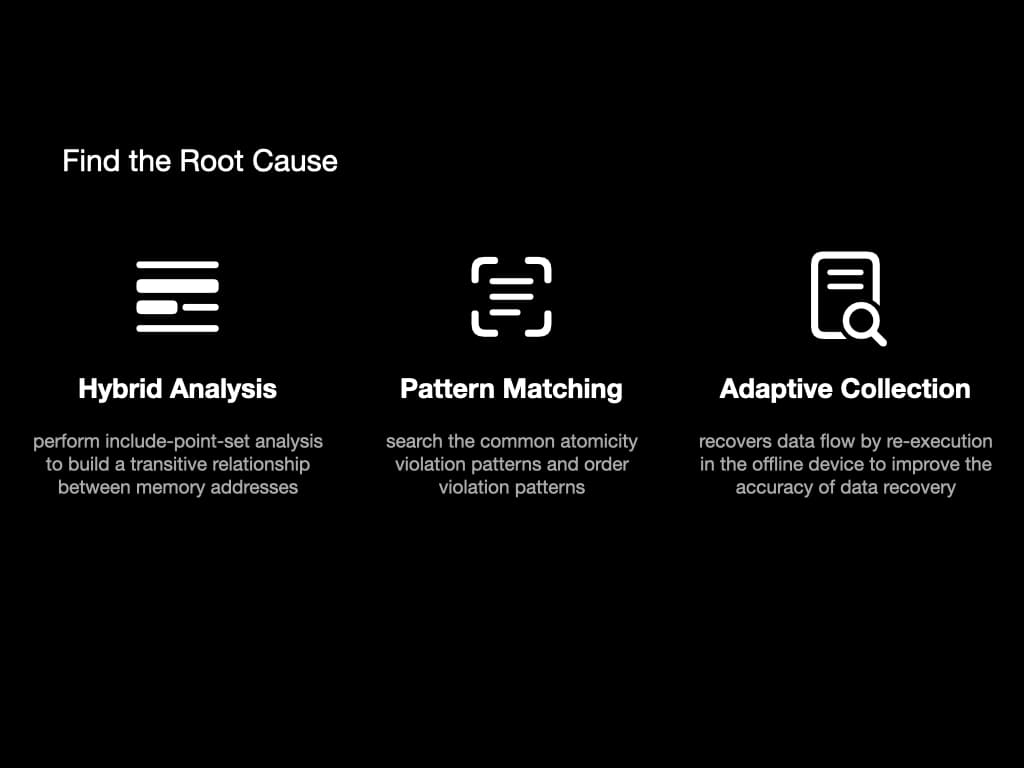
在混合分析中,我们执行称为"包含点集"的分析。它将在内存地址之间建立传递关系。基本上,它包含像"变量 x 受变量 y 影响"这样的信息。
在模式匹配中,我们搜索常见的原子性违规模式和顺序违规模式,以找到导致故障的关键指令。
自适应收集是一种帮助恢复数据流的方法。我们重新执行一些指令来提高数据恢复的准确性。
评估
Investigator 能够找到许多著名并发错误的根本原因。它也能够找到一些非并发错误的根本原因。
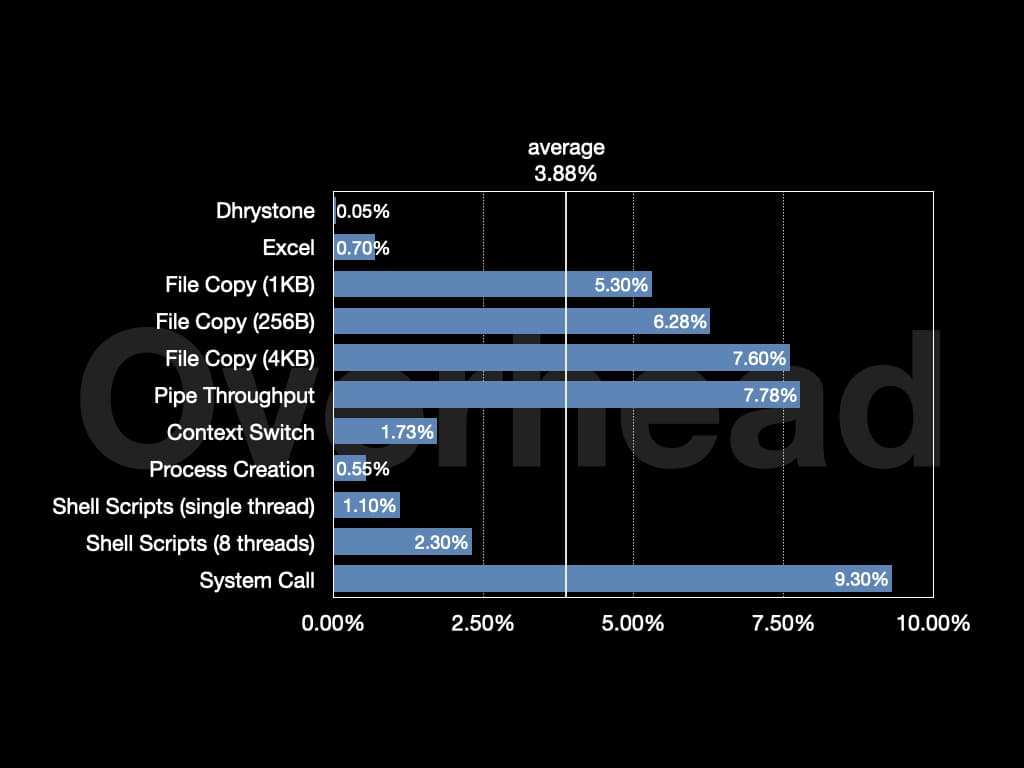
在 Unixbench 上的总体开销约为4%。在 Nginx 上,开销约为1.3%。
© LICENSED UNDER CC BY-NC-SA 4.0